linux系统slab内存占用
今天遇见了一个问题,发现一台系统为redhat 5.8的跑storm的机器内存报警,然后跟了一下,发现系统内存耗尽了,但是通过top或者ps命令看到所有应用或系统进程内存占用率总和不到10%。
[@storm-yd8325 ~]# free -m
total used free shared buffers cached
Mem: 64416 61273 3142 0 419 2597
-/+ buffers/cache: 58256 6159
Swap: 8189 0 8189
那50多G的内存哪去了呢?下面我们来分析一下。
1,查看了/proc/meminfo文件
它记录系统内存的分配使用信息的内核文件
[@storm-yd8325 ~]# cat /proc/meminfo
MemTotal: 65962124 kB
MemFree: 3229264 kB
Buffers: 429596 kB
Cached: 2658648 kB
SwapCached: 0 kB
Active: 12872252 kB
Inactive: 661388 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 65962124 kB
LowFree: 3229264 kB
SwapTotal: 8385920 kB
SwapFree: 8385920 kB
Dirty: 512 kB
Writeback: 0 kB
AnonPages: 10435932 kB
Mapped: 56312 kB
Slab: 49115748 kB
PageTables: 34376 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
CommitLimit: 41366980 kB
Committed_AS: 23772424 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 268472 kB
VmallocChunk: 34359468983 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
Hugepagesize: 2048 kB
如命令输出,发现系统slab分配器占用了将近50G的内存,终于发现了疑点。
那slab是什么呢?
slab是Linux操作系统的一种内存分配机制。其工作是针对一些经常分配并释放的对象,如进程描述符等,这些对象的大小一般比较小,如果直接采用伙伴系统来进行分配和释放,不仅会造成大量的内碎片,而且处理速度也太慢。而slab分配器是基于对象进行管理的,相同类型的对象归为一类(如进程描述符就是一类),每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
具体为:
采用伙伴算法分配内存时,每次至少分配一个页面。但当请求分配的内存大小为几十个字节或几百个字节时应该如何处理?如何在一个页面中分配小的内存区,小内存区的分配所产生的内碎片又如何解决?
Linux2.0采用的解决办法是建立了13个空闲区链表,它们的大小从32字节到132056字节。从Linux2.2开始,MM的开发者采用了一种叫做slab的分配模式,该模式早在1994年就被开发出来,用于Sun Microsystem Solaris 2.4操作系统中。Slab的提出主要是基于以下考虑:
1) 内核对内存区的分配取决于所存放数据的类型。例如,当给用户态进程分配页面时,内核调用get_free_page函数,并用0填充这个页面。 而给内核的数据结构分配页面时,事情没有这么简单,例如,要对数据结构所在的内存进行初始化、在不用时要收回它们所占用的内存。因此,Slab中引入了对象这个概念,所谓对象就是存放一组数据结构的内存区,其方法就是构造或析构函数,构造函数用于初始化数据结构所在的内存区,而析构函数收回相应的内存区。但为了便于理解,你也可以把对象直接看作内核的数据结构。为了避免重复初始化对象,Slab分配模式并不丢弃已分配的对象,而是释放但把它们依然保留在内存中。当以后又要请求分配同一对象时,就可以从内存获取而不用进行初始化,这是在Solaris 中引入Slab的基本思想。
实际上,Linux中对Slab分配模式有所改进,它对内存区的处理并不需要进行初始化或回收。出于效率的考虑,Linux并不调用对象的构造或析构函数,而是把指向这两个函数的指针都置为空。Linux中引入Slab的主要目的是为了减少对伙伴算法的调用次数。
2) 实际上,内核经常反复使用某一内存区。例如,只要内核创建一个新的进程,就要为该进程相关的数据结构(task_struct、打开文件对象等)分配内存区。当进程结束时,收回这些内存区。因为进程的创建和撤销非常频繁,因此,Linux的早期版本把大量的时间花费在反复分配或回收这些内存区上。从Linux2.2开始,把那些频繁使用的页面保存在高速缓存中并重新使用。
3) 可以根据对内存区的使用频率来对它分类。对于预期频繁使用的内存区,可以创建一组特定大小的专用缓冲区进行处理,以避免内碎片的产生。对于较少使用的内存区,可以创建一组通用缓冲区(如Linux2.0中所使用的2的幂次方)来处理,即使这种处理模式产生碎片,也对整个系统的性能影响不大。
4) 硬件高速缓存的使用,又为尽量减少对伙伴算法的调用提供了另一个理由,因为对伙伴算法的每次调用都会“弄脏”硬件高速缓存,因此,这就增加了对内存的平均访问次数。
Slab分配模式把对象分组放进缓冲区(尽管英文中使用了Cache这个词,但实际上指的是内存中的区域,而不是指硬件高速缓存)。因为缓冲区的组织和管理与硬件高速缓存的命中率密切相关,因此,Slab缓冲区并非由各个对象直接构成,而是由一连串的“大块(Slab)”构成,而每个大块中则包含了若干个同种类型的对象,这些对象或已被分配,或空闲,如图6.12所示。一般而言,对象分两种,一种是大对象,一种是小对象。所谓小对象,是指在一个页面中可以容纳下好几个对象的那种。例如,一个inode结构大约占300多个字节,因此,一个页面中可以容纳8个以上的inode结构,因此,inode结构就为小对象。Linux内核中把小于512字节的对象叫做小对象。实际上,缓冲区就是主存中的一片区域,把这片区域划分为多个块,每块就是一个Slab,每个Slab由一个或多个页面组成,每个Slab中存放的就是对象。
2,通过slabtop命令查看slab缓存信息
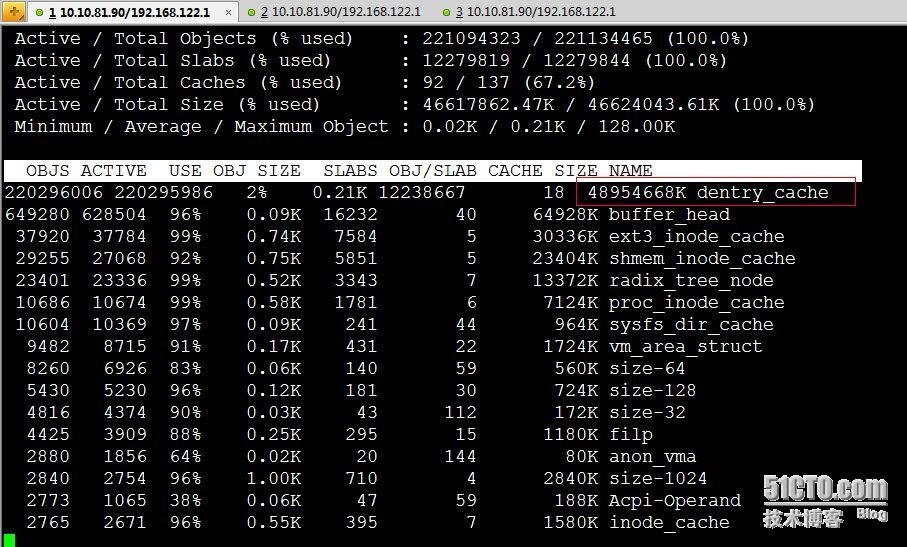
通过slabtop我们看到Linux系统中有大量的dentry_cache占用内存,那dentry_cache是什么呢?
首先,我们知道inode对应于物理磁盘上的具体对象,而dentry是一个内存实体,其中的d_inode成员指向对应的inode,故可以把dentry看成是Linux文件系统中某个索引节点(inode)的链接,这个索引节点可以是文件,也可以是目录。而dentry_cache是目录项高速缓存,是Linux为了提高目录项对象的处理效率而设计的,它记录了目录项到inode的映射关系。
3,结合storm服务分析
当前服务器是storm集群的节点,首先想到了storm相关的工作进程,strace一下storm的worker进程发现其中有非常频繁的stat系统调用发生,而且stat的文件总是新的文件名:
[@storm-yd8325 ~]# strace -fp 31984 -e trace=stat
进一步观察到storm的worker进程会在本地目录下频繁的创建、打开、关闭、删除心跳文件,每秒钟一个新的文件名:
[@storm-yd8325 ~]# sudo strace -fp 31984 -e trace=open,stat,close,unlink
总结:storm进程频繁的文件io操作,导致了dentry_cache占用了系统太多的内存资源。
4,系统的自动slab缓存回收
在slab缓存中,对象分为SReclaimable(可回收)和SUnreclaim(不可回收),而在系统中绝大多数对象都是可回收的。内核有一个参数,当系统内存使用到一定量的时候,会自动触动回收操作。
内核参数:
vm.min_free_kbytes = 836787
1)代表系统所保留空闲内存的最低限。
在系统初始化时会根据内存大小计算一个默认值,计算规则是:
min_free_kbytes = sqrt(lowmem_kbytes * 16) = 4 * sqrt(lowmem_kbytes)(注:lowmem_kbytes即可认为是系统内存大小)
另外,计算出来的值有最小最大限制,最小为128K,最大为64M。
可以看出,min_free_kbytes随着系统内存的增大不是线性增长,因为随着内存的增大,没有必要也线性的预留出过多的内存,能保证紧急时刻的使用量便足矣。
2)min_free_kbytes的主要用途是计算影响内存回收的三个参数 watermark[min/low/high]
(1) watermark[high] > watermark [low] > watermark[min],各个zone各一套
(2)在系统空闲内存低于 watermark[low]时,开始启动内核线程kswapd进行内存回收(每个zone一个),直到该zone的空闲内存数量达到watermark[high]后停止回收。如果上层申请内存的速度太快,导致空闲内存降至watermark[min]后,内核就会进行direct reclaim(直接回收),即直接在应用程序的进程上下文中进行回收,再用回收上来的空闲页满足内存申请,因此实际会阻塞应用程序,带来一定的响应延迟,而且可能会触发系统OOM。这是因为watermark[min]以下的内存属于系统的自留内存,用以满足特殊使用,所以不会给用户态的普通申请来用。
(3)三个watermark的计算方法:
watermark[min] = min_free_kbytes换算为page单位即可,假设为min_free_pages。(因为是每个zone各有一套watermark参数,实际计算效果是根据各个zone大小所占内存总大小的比例,而算出来的per zone min_free_pages)
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
所以中间的buffer量为 high – low = low – min = per_zone_min_free_pages * 1/4。因为min_free_kbytes = 4* sqrt(lowmem_kbytes),也可以看出中间的buffer量也是跟内存的增长速度成开方关系。
(4)可以通过/proc/zoneinfo查看每个zone的watermark
例如:
Node 0, zone DMA
pages free 3960
min 65
low 81
high 97
3)min_free_kbytes大小的影响
min_free_kbytes设的越大,watermark的线越高,同时三个线之间的buffer量也相应会增加。这意味着会较早的启动kswapd进行回收,且会回收上来较多的内存(直至watermark[high]才会停止),这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量。极端情况下设置min_free_kbytes接近内存大小时,留给应用程序的内存就会太少而可能会频繁地导致OOM的发生。
min_free_kbytes设的过小,则会导致系统预留内存过小。kswapd回收的过程中也会有少量的内存分配行为(会设上PF_MEMALLOC)标志,这个标志会允许kswapd使用预留内存;另外一种情况是被OOM选中杀死的进程在退出过程中,如果需要申请内存也可以使用预留部分。这两种情况下让他们使用预留内存可以避免系统进入deadlock状态。
5,最终结果
最终查明,slab cache占用过多属于正常问题,并且当内存到达系统最低空闲内存限制的话,会自动触发kswapd进程来回收内存,属于正常现象。
注:测了一下,当调整完min_free_kbytes值大于系统空闲内存后,kswapd进程的确从休眠状态进入运行态,开始回收内存。
根据我们跑的storm服务做出如下调整:
vm.vfs_cache_pressure = 200
该文件表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。