[zz]如何让 glog 性能提高 10 倍
背景
最近在给glog做性能优化, 使用c++版本 glog-0.3.4做压测,测试数据总量为1.5g, 起12个线程循环写133个字节的日志条目,测试结果耗时175s,每秒大约8-9MB的吞吐量。
在此测试基础上,我对glog进行了一系列的性能优化,优化后耗时16s,性能为glog原生版本的10倍。
优化过程
去localtime函数调用
查看glog源码,在获取日期的时候使用了localtime, localtime_r这两个函数,而这两个函数调用了__tz_convert, __tz_convert有tzset_lock全局锁,每次获取时间都会使用到kernel级别的futex锁,所以优化第一步是去掉glibc的localtime函数,使用getimeofday获取秒数和时区,用纯耗cpu的方式算出日期,稍微复杂一点的计算就是闰年闰月的转换。将这段函数替换后,耗时从175s减少成46s,性能瞬间提高4-5倍。
减少锁粒度
再翻看glog的源码,glog是一个多线程同步写的操作,简化代码就是 lock();dosomething();fwrite();unlock(); fwrite本身就是线程安全的,缩小锁粒度需要改成lock();dosomething();unlock();fwrite(); 其他变量都比较好处理,比如文件名之类的,不好处理的是轮转的时候会更改fd, fwrite()会使用到fd。我使用了指针托管和引用计数的办法,当轮转文件时,将current_fd_ 赋值给old_fd_, 不直接delete或fclose, 简化代码等于:lock();dosomething();if(true) old_fd_ = current_fd_; currnt_fd_.incr();unlock();fwrite();currnt_fd_.decr(); 当old_fd_ = 0时,才会真正delete 和fclose 这个fd指针。优化后压测耗时30s。
引入无锁队列异步IO化
从第二次优化来看。锁热点已经很少了,性能也有不少提升,已经能满足OCS的需求,但是这种多线程同步堵塞写io的模式,一旦出现io hang住的情况,所有worker线程都会堵住。可以看下__IO_fwrite 这个函数,在写之前会进行__IO_acquire_lock() 锁住,写完后解锁。
为了避免所有线程卡住的情况,需要将多线程同步堵塞转换成单线程异步的io操作,同时避免引入新的锁消耗性能,所以引入无锁队列,算法复杂度为O(1),结构如图所示:
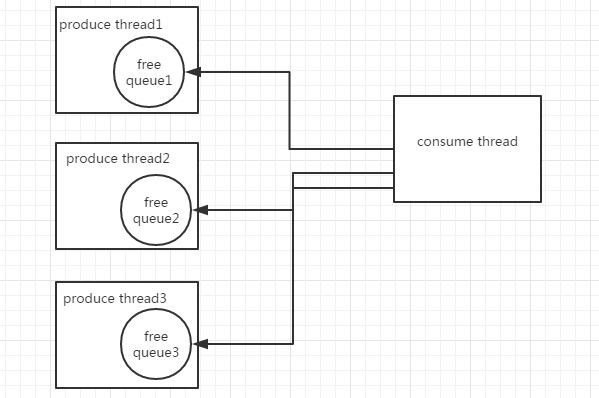
每个生产者线程都有独自的无锁队列,生产者线程做日志的序列化处理等,整个glog有一个单线程的消费线程,消费线程只处理真正的io请求,无锁队列使用环形数组实现,引入tcmalloc做内存管理。消费线程也会有hang住的可能,因为无锁队列使用CAS,当队列满了的时候并不会无限增长内存,而是会重试几次后放弃本次操作,避免内存暴涨。改造后耗时33s。
小细节优化
glog在linux系统下缺省使用的是pthread_rw_lock,在第二步减少锁粒度的基础上,现已不需要内核态的读写锁,所以将rwlock替换成用户态的spinlock。另外__GI_fwrite的热点还是有一些,采用合并队列的方法减少一些写操作,再加上超时机制,防止缓存的日志不及时落地。总结起来的优化就是:
- 向前合并队列写
- glog缺省使用的读写锁和mutex锁,换成spinlock
- 单条message buffer大小调整
- fwrite设置file buffer
这些优化完成后耗时时间为16s。
使用场景
优化后的glog版本适合使用在需要高日志吞吐量的产品, 比如OCS这种分布式高并发高吞吐量的系统。
高性能日志系统总结
从以上优化可以总结出高性能的日志系统的特性:
- 使用异步IO实现高并发的日志吞吐量,日志线程与worker线程解耦,worker线程只做序列化之类的工作,日志线程只做io,避免当磁盘满了等异常情况发生时主路径阻塞导致服务完全不可用,这在任何一个高并发的系统中都需要注意的。
- 其他细节点特性:
- 不使用localtime取日期,单测localtime和getimeofday 获取时间, gettimeofday 速度比localtime快20倍
- 选用无锁队列可重试放弃操作,避免内存暴涨。
- 使用内存池管理,比如tcmalloc
- 对fd等关键指针做引用计数处理,避免大粒度的锁。